Trellis 从 0 到 1 使用笔记
适用场景:我在 Codex 终端里学习和使用 Trellis。
当前版本范围:先搭完整课件大纲,并优先整理
$start的使用。$start之前的准备、安装、初始化等内容,后续再按课件顺序逐章补充。
这份笔记怎么用
如果我以后只是想快速复习,不要一上来就从头慢慢读完整篇。更稳的用法是:
- 先看最后的“一页总结”,先把大框架和命令顺序过一遍。
- 再看各章结尾的“本章 3 句速记”,快速找回这一章的核心。
- 只有当我某一块又混了,才回头读那一章的正文细节和推导过程。
也就是说,这份笔记不是只能从头看到尾,它已经被分成了:
- 长版主笔记:保留完整理解、误区、边界和思考过程
- 章节速记层:每章末尾的“本章 3 句速记”
- 临时速查层:最后的“一页总结”
这份笔记以后怎么补写最顺
这部分我最好也提前记住,不然以后很容易又回到低效路径。
对这份 trellis-study-notes 来说,后续补写的成功路径应该是:
- 我只需要直接说“继续第几章”或者“补哪一块”。
- 如果这一章边界已经清楚,AI 就直接落文档,不要让我反复确认。
- 如果这一章确实容易混,AI 先用很短的对话帮我理清关键边界,然后直接落文档。
- 不要让我为了继续补笔记,反复点很多次回车,或者重复走之前已经证明不顺的路径。
一句话记忆:
这份笔记后续最顺的推进方式,是“我点章节,你先判断清不清楚;清楚就直接写,不清楚就短对话后直接写”。
这到底是什么?
如果让我现在用一句最白话的话解释 Trellis,我会这样记:
Trellis 是一套让 AI 按项目流程干活的工作流壳子。
这里最重要的不是“壳子”这个词,而是“按项目流程干活”。
因为没有 Trellis 的时候,AI 很容易变成一种“随便聊聊就开始干”的状态。你说一句需求,它就开始改;你再补一句,它再跟着补;聊着聊着,很多重要东西其实只存在聊天记录里,没有真正落到项目本身。
这会带来几个很现实的问题:
- 这次到底在做什么,不够稳定
- 做到哪一步了,不够清楚
- 哪些是已经确认的范围,哪些只是临时聊到,不够明确
- 对话一长,AI 容易变钝、变忘,前面确认过的东西可能慢慢丢掉
也就是说,没有 Trellis 时,AI 更像一个“边聊边即兴发挥的助手”。
而有了 Trellis 以后,事情会开始变得不一样。
AI 不再只是跟着你一句一句聊天往前冲,而是开始围绕这些东西工作:
- 任务:这次到底在做什么
- 规范:这个项目希望怎么做
- 记录:前面已经确认过什么
这样一来,AI 的工作方式就从“随便聊聊”慢慢变成“按项目流程协作”。
这里我觉得最关键的一点是:Trellis 不能让 AI 永远不忘,但它能把重要信息从聊天里搬到文件里。
比如:
- 当前任务会落到
.trellis/tasks/ - 需求和边界会落到
prd.md - 项目规矩会落到
.trellis/spec/ - 会话过程和结论以后还可以落到
.trellis/workspace/
这样就算当前会话很长,或者你下次重新开一轮,关键状态也不是全靠聊天硬记,而是可以重新读回来。
这个点其实我们刚刚已经真实体验到了。
我们前面这段对话已经聊了很长,范围也从 Trellis 基础用法、$start、课件内容,一路推进到学习笔记怎么写。如果没有 Trellis,这些决定大概率就只是散落在聊天记录里。对话一长,我会更容易忘;你下次回来,也更难快速接上。
但现在不一样,因为我们已经做了几件很关键的事:
- 挂了
trellis-study-notes这个任务 - 把任务目标和范围写进了
prd.md - 把已经确定的内容写进了
trellis-study-notes.md
所以就算这轮对话继续变长,或者我们干脆下一轮再继续,第 1 章到底想写什么、整份笔记现在做到哪,都不是完全悬空的。
如果我要给这一章最后收一句最核心的话,我会记成:
Trellis 的本质,是把 AI 从“随便聊聊”变成“按项目流程协作”。
本章 3 句速记
- Trellis 最核心的作用,不是让 AI 更会聊天,而是让 AI 围绕任务、规范和记录来协作。
- 关键状态要尽量落到
.trellis/tasks/、prd.md、笔记文件这些项目文件里,而不是只留在对话里。 - 以后重新开会话时,我恢复进度靠的是“重新读项目状态”,不是指望 AI 永远记得。
有它没它的区别
如果第 1 章是在回答“它是什么”,那这一章更像是在回答:
为什么我不能就直接和 AI 聊,非要多加一个 Trellis?
我现在自己的答案很明确:
没有 Trellis 时,AI 更像一个临时聊天助手;有了 Trellis 时,AI 开始更像一个围绕任务和流程工作的项目协作者。
这两者差别看起来像只是“多了一层流程”,但实际体感差很多。
先说没有 Trellis 的感觉。
没有 Trellis 时,我和 AI 的关系更像是“边聊边推进”。我想到什么就问什么,AI 也会立刻跟着往前走。这样当然不是不能用,甚至很多时候还挺方便,但它更像一种临时协助,而不是一种稳定协作。
这种状态下,AI 更像一个临时聊天助手。它会回应我、配合我、给我建议,但整件事主要还是靠当前这段对话在往前推。只要问题一变复杂、范围一拉长,很多东西就会开始变得不稳定。
比如:
- 现在到底在解决哪个问题,容易漂
- 哪些话是随口一说,哪些已经算正式决定,不够清楚
- 一旦话题变多,重点容易散开
- 对话一长,前面说过的话就更容易失焦
所以没有 Trellis 时,最大的感觉不是“完全不能做事”,而是:
能做,但更像临场发挥。
而有了 Trellis 以后,感觉会明显变掉。
我不是单纯在和 AI 聊天,而是在一个已经有任务、结构和流程约束的框架里推进事情。AI 也不再只是顺着我这几句话临时发挥,而是开始围绕项目中的这些东西工作:
- 任务
- 结构
- 规范
- 记录
这时它更像一个项目协作者,而不是临时聊天助手。
我觉得这里最根上的差别,不在 AI 本身,而在于:
有没有任务、结构和流程约束。
没有这些约束时,AI 主要靠当前聊天往前推;有了这些约束以后,AI 才真正被放进一个稳定的工作框架里。
这也是为什么我现在越来越感觉,Trellis 的价值不只是“让事情更规整”,而是它真的会改变我自己的思考方式。
有了这个框架以后,我现在最明显的体感变化有三个:
- 整理笔记时,思考量明显变大了
- 严谨性明显增强了
- AI 也越来越懂我了
这里的“越来越懂我”,不是一种神秘的“它突然变聪明了”,而是因为:
- 我的任务在积累
- 我的表达偏好在积累
- 我的判断方式在积累
- 我的阶段性结论也在积累
所以我会越来越有一种感觉:
有了 Trellis,AI 不只是更高效,而是开始更像一个被我持续校准的协作者。
再往前推一步,我觉得这一章最值得记住的亮点其实是这句:
Trellis 不只是提高效率,它还会逼着我把思考变得更有结构。
因为一旦进入这种任务和章节化的框架里,很多原本可以模糊带过的东西,现在都得被问清楚:
- 这一章到底在讲什么
- 核心定义是哪一句
- 跟上一章的区别是什么
- 先写什么,后写什么
- 最后要收束到哪里
这会逼着我不只是“想到一些东西”,而是把想法慢慢压成结构。
所以如果我要把这一章最后收束成一句更强的话,我现在会这样记:
有了 Trellis,AI 会越来越像一个被我持续校准的外部脑。
前提不是我把脑子交给它,而是我不断把自己的判断方式、表达偏好和阶段性结论训练进这个系统里。
这也是我现在越来越觉得它好用的根本原因。
本章 3 句速记
- 没有 Trellis 时,AI 更像临时聊天助手;有了 Trellis 后,它更像围绕任务工作的协作者。
- Trellis 的价值不只是提高效率,更是把任务、结构、规范和记录固定下来。
- 它会让 AI 越来越像一个被我持续校准的外部脑,但前提是我把判断和结论不断沉淀进项目。
先学会用终端(3 分钟速成)
如果我要先给未来的自己打一针定心针,我会先记住这句:
终端不是什么很黑客的东西,它只是一个用打字方式操作电脑和工具的地方。
很多人一看到黑底白字,就会下意识觉得“这很高级”“这应该很难”。但对我现在这种使用场景来说,终端并不神秘。它本质上只是一个输入命令、让电脑和工具按我意思做事的地方。
所以第一个要纠正的心态不是“我要先学很多命令”,而是:
我不用先把终端学明白才开始用,很多时候先用,不懂就问 AI。
这也是我现在更适合的学习方式。先敢用,先让事情跑起来,哪里不懂就马上问,而不是要求自己一上来就把终端系统性学完。
对现在的我来说,终端最重要的不是“会很多”,而是先会最少但够用的几个命令。
最少但够用的 5 个命令
pwd
作用:看我当前在哪个目录。
什么时候最有用:
- 我怀疑自己不在项目目录里
- 我刚切换完目录,想确认位置
- AI 让我先确认当前路径
例子:
pwd
看到类似:
D:\ai_development\codex_demo
就说明我现在就在这个项目目录里。
cd
作用:切换目录。
什么时候最有用:
- 进入某个项目目录
- 从系统目录切回自己的项目目录
- 切到别的文件夹继续工作
例子:
cd D:\ai_development\codex_demo
一句话理解:cd 就是在告诉终端“我现在去这个文件夹里工作”。
dir
作用:看当前目录里有什么文件和文件夹。
什么时候最有用:
- 想看看项目根目录里有哪些东西
- 想确认某个文件是不是已经存在
- 想快速认识一个陌生目录
例子:
dir
在 Windows / PowerShell 里,这个命令很顺手,因为它能直接把当前目录下的内容列出来。
git status
作用:看项目当前状态。
这是我现在最该养成习惯的命令之一,因为它会告诉我:
- 有没有还没提交的改动
- 当前工作区是不是干净的
- 我到底处在一个什么状态里
例子:
git status
你刚刚已经真的用过它一次,而且结果很关键:
nothing to commit, working tree clean
这句话的意思就是:
这次提交已经成功了,当前工作区是干净的。
git log --oneline -1
作用:快速看最近一条提交。
什么时候最有用:
- 我刚提交完,想确认提交是否真的成功
- 我想看最近一次 commit 的哈希和标题
- 后面执行
$record-session时,我需要最近提交的信息
例子:
git log --oneline -1
你刚刚已经真实跑出了结果,比如:
70efa3a chore(trellis): bootstrap workflow and add study notes
这就说明:
- 最近一条提交已经存在
- 提交哈希是
70efa3a - 提交信息是
chore(trellis): bootstrap workflow and add study notes
这类命令非常适合新手,因为它不是为了“炫技”,而是为了给自己一个确定感:
我刚才那一步到底有没有成功。
项目里常见的工具命令
上面 5 个命令是“最少但够用”的第一批。除此之外,我也要先认得几个项目工具长什么样,不用一下子全懂,但至少知道它们是做什么的。
python
作用:运行 Python 相关脚本或查看 Python 环境。
比如 Trellis 这个项目里,就经常会遇到这种命令:
python ./.trellis/scripts/get_context.py
这类命令不用先学底层原理,先知道“这是在执行项目里的 Python 脚本”就够了。
trellis
作用:运行 Trellis 自己的命令。
比如:
trellis --version
trellis init -u 你的名字
看到 trellis 开头,就先把它理解成:
这是在调用 Trellis 这个工具本身。
claude / codex
作用:启动 AI 编程助手,进入项目协作会话。
课件里常见的是:
claude
而我现在的实际场景更接近 Codex,所以对我来说,更重要的是理解这类命令背后的意义:
不是单纯开一个聊天窗口,而是进入项目里的 AI 协作环境。
这一章我现在最该记住什么
如果我现在还是新手,那这一章不用背很多东西,只要先记住这些就够了:
- 终端不是什么很黑客的东西
- 它只是一个用打字方式操作电脑和工具的地方
- 我不用先全懂,先会最少几个命令就够了
- 不懂的时候可以直接问 AI
- 对我现在最实用的第一批命令是:
pwd、cd、dir、git status、git log --oneline -1
最后用一句最适合收尾的话记住这一章:
终端不是要我一下子学会很多,而是让我先敢用,边用边懂。
本章 3 句速记
- 终端不是什么很黑客的东西,它只是一个用打字方式操作电脑和工具的地方。
- 对现在的我来说,先会
pwd、cd、dir、git status、git log --oneline -1就够用了。 - 终端不用先全懂,先敢用,不懂就及时问 AI。
准备工作
如果我要先用一句最白话的话记这一章,我会记成:
这一章不是在装 Trellis,而是在确认电脑已经具备“让 Trellis 跑起来”的基础环境。
很多新手一看到“安装 Trellis”,会下意识以为只要装一个 Trellis 就行了。其实不是。
Trellis 更像是建立在几样基础工具之上的一层工作流:
Node.js负责让npm和 Trellis 这类 JavaScript 工具跑起来Git负责让项目有版本记录,也让任务和改动有落点Python负责支撑 Trellis 里一部分脚本- AI CLI 工具负责真正和我协作,比如课件里的
Claude Code,或者我现在实际在用的Codex
所以这一章和下一章要分开理解:
- 第 4 章:先把地基准备好
- 第 5 章:再正式安装 Trellis
开始前要先装好的 4 样东西
Node.js
这是最先要准备的东西,因为 Trellis 本身是基于 JavaScript 生态分发的,后面安装 Trellis 要用到的 npm,就是跟着 Node.js 一起装上的。
如果我要用最白话的话理解它,可以记成:
没有 Node.js,后面的 npm install -g @mindfoldhq/trellis@latest 就跑不起来。
对我这种使用者来说,不需要先懂 JavaScript,只要知道:
- Trellis 要靠它安装
npm通常会跟着它一起出现- 这是后面装 Trellis 的前提条件
Git
Git 可以先把它理解成代码世界里的“存档系统”或者“后悔药”。
Trellis 为什么也离不开它?因为 Trellis 不只是聊天,它还很强调:
- 当前任务做到哪
- 改了哪些文件
- 什么时候该提交
- 什么时候适合记录 session
这些事情都和版本记录有关系。所以如果没有 Git,后面的工作流会很不完整。
对现在的我来说,只要先记住这句就够了:
git commit 很像打游戏存档,而 Trellis 会围绕这些“存档点”来组织工作。
Python
这一项最容易让人误会,因为很多人会想:“我不是没在学 Python 吗,为什么还要装?”
答案是:不是因为我要先学 Python,而是因为 Trellis 的一部分内部脚本会用到它。
所以这一章里,Python 的定位不是“我要拿它写程序”,而是“我先把 Trellis 依赖的环境准备好”。
对 Windows 用户尤其要多记一件事:
安装 Python 时,记得勾选 Add to PATH。
不然很容易出现“明明装了,但终端里找不到 python”的情况。
AI CLI 工具:Claude Code 或 Codex
课件原文这里写的是 Claude Code,因为教程主场景是 Claude Code。
但对我当前这份笔记来说,这里更适合记成:
你需要先装好一个真正会在终端里和你协作的 AI CLI 工具。
常见可以这样对应理解:
- 如果你跟的是原课件:这一项就是
Claude Code - 如果你现在主要在 Codex 里做事:这一项就理解成
Codex
也就是说,这一项的本质不是“必须是某一个品牌”,而是:
Trellis 需要和一个实际工作的 AI 终端工具配合。
我可以怎么快速理解这 4 样东西的分工
| 工具 | 最白话的作用 | 为什么 Trellis 需要它 |
|---|---|---|
Node.js |
让 JavaScript 工具能跑起来 | 安装 Trellis 要靠 npm |
Git |
给代码做版本存档 | Trellis 很多任务流都依赖版本状态 |
Python |
让部分脚本能执行 | .trellis/scripts/ 里有脚本会用到 |
Claude Code / Codex |
真正和我协作的 AI CLI | Trellis 不是单独聊天窗口,而是 AI 工作流外壳 |
装完以后怎么检查
这一段很重要,因为“我以为装好了”和“终端真的认得这个命令”是两回事。
最稳的做法不是凭感觉,而是直接在终端里检查:
node -v
git --version
python --version
codex --version
如果你跟的是原课件里的 Claude Code 场景,就把最后一条换成:
claude --version
看到什么结果算基本正常?
node -v:能看到版本号,且最好是v18以上git --version:能看到版本号就行python --version:能看到版本号,且最好是3.8以上codex --version或claude --version:能看到版本号就行
对我现在这种新手使用方式来说,不需要先研究版本号细节,先把重点放在:
命令输下去之后,终端到底认不认它。
如果命令不认,通常说明什么
最常见的报错信号就是这两类:
command not found- “不是内部或外部命令,也不是可运行的程序或批处理文件”
如果出现这些提示,通常说明的是:
- 这个软件还没装好
- 装好了,但终端还没重新打开
- 装好了,但环境变量没配好
对 Windows 来说,最容易踩的两个坑是:
- Python 安装时没勾
Add to PATH - 刚装完软件,没有关掉终端再重新打开
所以排查顺序可以先记成:
- 先确认自己到底有没有装
- 关掉终端重新打开一次
- 再跑一遍版本检查命令
- 还是不行,再回去重装或检查 PATH
这一章和下一章不要混
我最好把这两章明确分开,不然很容易脑子里混在一起:
- 第 4 章问的是:电脑环境准备好了没有
- 第 5 章问的是:Trellis 这个工具本身装好了没有
也就是说,第 4 章检查通过,只代表我已经具备了继续往下走的条件;真正安装 Trellis,还要到下一章执行:
npm install -g @mindfoldhq/trellis@latest
这一章我现在最该记住什么
- Trellis 不是孤零零单独运行的,它站在一组基础工具之上
- 这组基础工具里,最关键的是:
Node.js、Git、Python、AI CLI 工具 - 课件里这项 AI 工具写的是
Claude Code,我在 Codex 场景里可以映射成Codex - “装好了”不靠猜,直接用
--version或-v检查 - 第 4 章是准备地基,第 5 章才是正式安装 Trellis
最后用一句最适合收尾的话记住这一章:
先把环境准备对,后面的 Trellis 工作流才会顺。
本章 3 句速记
- 第 4 章讲的是准备地基,也就是
Node.js、Git、Python和 AI CLI 这些前置工具。 - 判断有没有装好,不靠猜,直接用
--version或-v去检查。 - 这一章只是把环境备好,真正安装 Trellis 是下一章的事。
安装 Trellis
如果我要先给未来的自己一句总提醒,我会先记住这句:
这一章讲的是把 Trellis 这个工具装到电脑里,还不是正式开始某个项目。
我当时最容易混淆的点,不是命令怎么敲,而是下面这三件事表面都像“开始用 Trellis”,其实根本不是同一层:
npm install -g @mindfoldhq/trellis@latest
这是把 Trellis 装到这台电脑里trellis init ...
这是把 Trellis 接进某个具体项目$start
这是进入当前项目会话,让 AI 读取上下文开始协作
所以第 5 章只讲第一层,也就是:
先让这台电脑以后认得 trellis 这个命令。
这一章真正要做的事是什么
这一章不是在“创建项目”,也不是在“正式进入任务流”。
它更像是在做一件很基础但很关键的事:
先把 Trellis 安装成这台电脑里随时可调用的工具。
如果我以后再忘了这一章的定位,可以直接这样回忆:
- 第 4 章解决“环境够不够”
- 第 5 章解决“电脑里有没有 Trellis 这个工具”
- 第 6 章以后才开始进入“项目里怎么真正用它”
安装命令长什么样
npm install -g @mindfoldhq/trellis@latest
这条命令看着长,但其实每一段都能拆开理解。
npm
可以先把它理解成 Node.js 生态里的“安装员”。
我不是直接对 Trellis 说“你给我装上”,而是在对 npm 说:
请你帮我把一个工具安装到电脑里。
所以看到 npm,先不要慌,它不是 Trellis 本身,而是负责安装 Trellis 的那个人。
install
这一段最简单,就是“安装”。
也就是说,我整条命令的核心动作其实就是:
让 npm 去安装一个包。
-g
这一段对小白特别重要,最好单独记。
-g 是 global 的意思,可以先把它理解成:
不是只装在当前项目文件夹里,而是装到这台电脑都能用。
如果想用类比来记,可以这样想:
- 不带
-g
更像把工具放进当前房间的小抽屉里 - 带
-g
更像把工具放进整套房子的公共工具柜里
所以这里为什么要带 -g?
因为 Trellis 更像一个命令行工具,而不是某个项目内部才用得到的局部依赖。
我装好以后,希望以后在不同项目目录里都能直接输入:
trellis
或者:
trellis init -u 我的名字
而不是每换一个项目都重新安装一遍。
如果只记一句,就记这个:
-g 的作用,是让 Trellis 变成“这台电脑里随处可用的工具”。
@mindfoldhq/trellis
这一段就是 Trellis 这个包本体的名字。
可以先理解成:
我现在告诉 npm,我要安装的那个工具就叫这个名字。
这里最重要的不是死记包名,而是知道:
npm是安装工具的人@mindfoldhq/trellis是被安装的对象
@latest
这一段可以理解成:
给我装当前最新版本。
所以整条命令如果翻成人话,大概就是:
请用 npm,把最新版 Trellis 全局安装到这台电脑里。
这一步通常做几次
这一步最适合记成:
npm install -g @mindfoldhq/trellis@latest 这一步,通常一台电脑只需要做一次。
也就是说,它不是那种“每次开新项目都先装一遍”的动作。
真正更接近“每个项目一次”的,反而是后面的:
trellis init -u 你的名字
所以以后如果脑子一混,就这样分:
- 安装 Trellis:按电脑算
trellis init:按项目算$start:按会话算
装完以后,我到底得到了什么
装完 Trellis 后,我真正得到的是:
- 这台电脑已经认得
trellis这个命令 - 以后我可以在项目目录里运行
trellis init - 后面我也可以用
trellis --version之类的命令检查工具状态
但我还没有得到的是:
- 某个具体项目已经接入 Trellis
- 当前项目已经自动生成
.trellis/结构 - AI 已经进入当前任务上下文
这一点特别容易混,所以最好直接记一句:
装完 Trellis,不等于项目已经能用了。
对一个新项目来说,后面通常还要继续两步:
- 先确认它是不是 Git 仓库
- 再执行
trellis init
那 git init 和 trellis init 到底怎么分
这个边界我当时也很容易混。
现在最适合写给未来自己的理解是:
git init
是先给这个项目装上“版本存档系统”trellis init
是再给这个项目接上“AI 协作工作流”
所以如果是一个全新的本地空项目,通常顺序更像这样:
git init
trellis init -u 你的名字 --claude --skip-existing
如果这是从 GitHub clone 下来的项目,往往已经有 .git 了,这时候一般不用再 git init,而是直接考虑 trellis init。
一句话记忆:
安装 Trellis 是装工具,git init 是让项目有版本管理,trellis init 是让项目接入 Trellis。
课件里的 trellis init 为什么长这样
你看到的视频里,命令是这样的:
trellis init -u 你的名字 --claude --skip-existing
这条命令也可以拆开理解:
trellis init
在当前项目里初始化 Trellis-u 你的名字
给当前开发者身份命名--claude
按 Claude Code 场景把对应集成也加进去--skip-existing
如果某些文件已经存在,就跳过,不强行覆盖
如果我现在主要在 Codex 里用 Trellis,那最重要的理解不是死盯着 --claude 这几个字,而是看懂它的角色:
它表示“我要给当前项目补哪一种 AI CLI 的集成”。
也就是说:
- 视频里用
--claude,因为它按 Claude Code 场景演示 - 如果我主要是 Codex 场景,就更该理解成
--codex
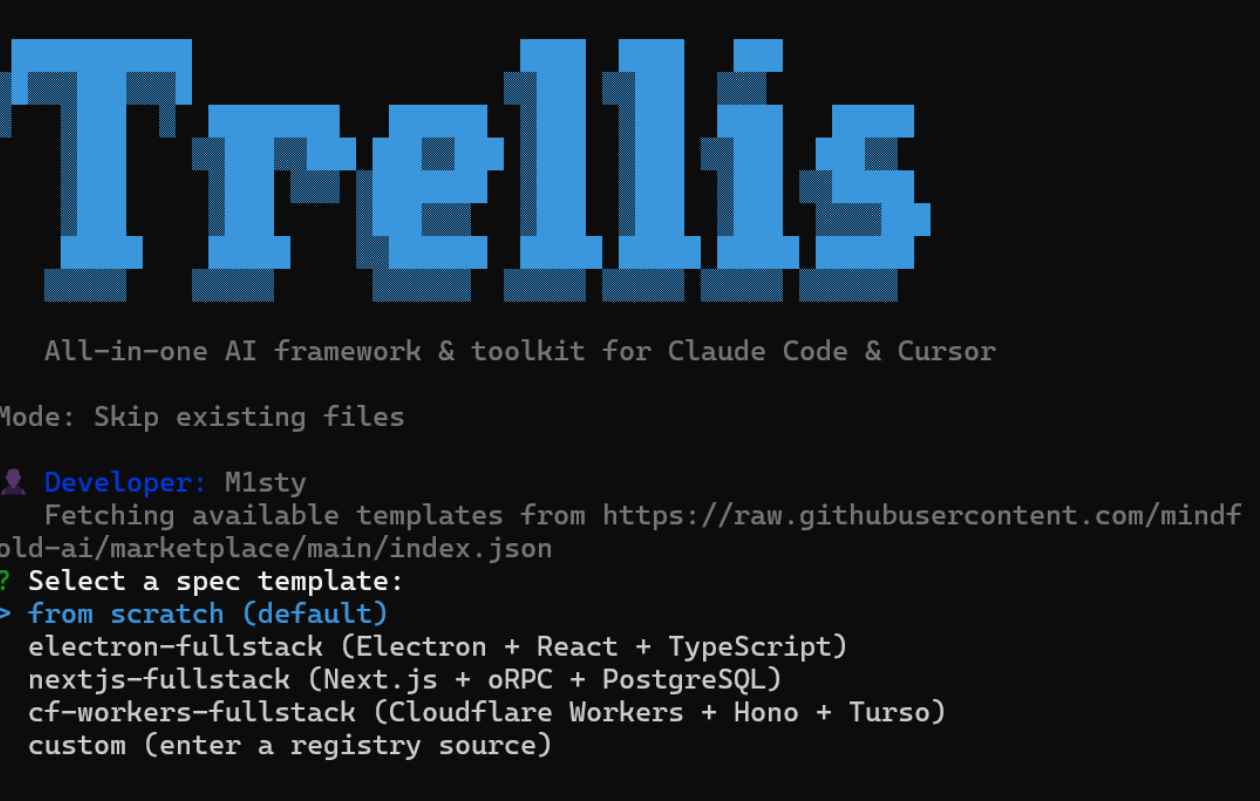
你图里这个界面,说明了什么
你补的这张图很有价值,因为它正好提醒了一件容易被忽略的事:
trellis init 不只是机械地写文件,它还可能继续问你“这个项目想用什么模板、什么集成方式”。
图里我能读出的几个关键点是:
- 当前模式是
Skip existing files - 已经识别出开发者名字
M1sty - 它正在让你选择一个 spec template
- 默认选项是
from scratch - 下面还给了像
electron-fullstack、nextjs-fullstack这样的现成模板
对未来的我来说,这个界面最值得记住的不是“长什么样”,而是:
trellis init 的结果不只取决于我敲了命令,还取决于我接下来在初始化界面里怎么选。
from scratch 该怎么理解
图里默认选项是:
from scratch (default)
这个选项最适合我现在这样理解:
从零开始生成一套基础 Trellis 结构,不额外套某个现成项目模板。
如果是学习、试用、或者当前项目本来就不是那几个官方模板场景,通常先选它最稳。
而像这些选项:
electron-fullstacknextjs-fullstackcf-workers-fullstack
更像是:
如果你的项目本来就很接近某种技术栈,它可以顺手给你带入更贴近该栈的 spec 模板。
所以这张图也顺手帮我记住了一件事:
初始化项目时,我不只是“有没有装 Trellis”,还会遇到“要不要选模板”这个决策。
这一章和下一章怎么衔接
到这一章结束时,我最应该确认的不是“我已经开始开发了”,而是:
- 这台电脑已经装好了 Trellis
- 我知道安装命令每一段大概是什么意思
- 我知道这一步通常一台电脑只做一次
- 我知道它和
git init、trellis init、$start分别属于不同层次 - 我也知道项目首次接入时,可能会进入模板选择界面
所以这章最后最适合收束成一句话:
这一章结束时,我得到的是“这台电脑已经能用 Trellis 了”;真正进入某个项目,还要继续看 git init、trellis init 和后面的实际工作流。
本章 3 句速记
npm install -g @mindfoldhq/trellis@latest是把 Trellis 装到电脑里,不是把项目已经接好。- 安装通常按电脑算一次,项目首次接入通常再看
git init和trellis init。 trellis init还可能继续让我选 CLI 集成和模板,比如--claude、--codex、from scratch。
完整实战:从零到一做个项目
如果我要先给未来的自己一句最重要的话,我会先记成:
这一章不是在演示“怎么让 AI 开发一个待办 App”,而是在演示“我怎么用 Trellis 持续推进一个真实任务”。
课件原本这里用的是“从零到一做个待办事项 App”。
但对我来说,直接换成“持续整理 trellis-study-notes 这份学习笔记”更好理解,因为这是我已经真实在做的任务,不是想象中的 demo。
不过也要顺手提醒自己:
这个案例和待办 App 不一样,它不是典型的代码开发任务,而是一个文档型、学习型、持续补写型任务。
也正因为这样,它反而更能说明 Trellis 的另一个价值:
Trellis 不只适合写代码,它也适合这种需要多轮推进、持续恢复上下文的任务。
为什么我用这份笔记当实战例子
如果继续照课件硬写待办 App,当然也不是不行,但对未来的我来说,复习时会少一种“这就是我真的这样用过”的确定感。
而这份 trellis-study-notes 则不一样:
- 我已经真实创建并推进过这个任务
- 我已经在同一个项目里连续补了好几章
- 我已经真实体验过“先对话澄清,再落文档”和“直接整理进文档”两种推进方式
所以这一章如果拿它当案例,会比一个虚构的待办 App 更贴近我后面真正会怎么用 Trellis。
这个案例和待办 App 有什么不同
这点最好单独记一下,不然后面容易误解成“所有 Trellis 实战都长一样”。
待办 App 更像:
- 功能开发型任务
- 更快进入写代码、改页面、跑效果
- 产物主要是代码、组件、页面和功能
而这份学习笔记更像:
- 持续整理型任务
- 更常先对话澄清理解,再沉淀成文字
- 产物主要是任务记录、PRD 和最终 Markdown 笔记
所以这一章的重点不是“AI 帮我做出一个页面”,而是:
AI 怎么在 Trellis 里,跟着我把一件会跨越多轮对话的任务稳定地继续下去。
第一步:我不是新开 demo,而是在真实项目里继续工作
这次实战不是从空白目录开始,也不是新建一个 todo-app 文件夹。
我是在真实仓库里继续工作,也就是当前这个项目:
codex_demo
而且这个项目不是刚接入 Trellis 的状态,而是已经:
- 装好了 Trellis
- 建好了
.trellis/结构 - 已经存在正在推进的任务
这里最值得记住的一点是:
很多时候,Trellis 的真实用法不是“从零开始创建一切”,而是“回到一个已经在推进中的项目里继续做”。
第二步:先 $start,不是立刻写,而是先回到项目上下文
这一步和普通聊天最大的区别就在这里。
我不是一上来就把新需求往 AI 脸上扔,而是先用:
$start
让 AI 先回到当前项目状态。
这一步最适合怎么记?
不是让 AI 立刻干活,而是先让它把当前项目里的关键信息重新读回来。
这里它通常会去读或者确认这些内容:
.trellis/workflow.md- 当前 developer 身份
- 当前任务状态
.trellis/tasks/里的任务信息- 相关规范索引和上下文文件
这也是为什么 $start 之后,我不用每次都重新从头解释背景。
第三步:AI 识别到当前任务是 trellis-study-notes
这一步是 Trellis 真正开始和普通聊天拉开差距的地方。
在这个案例里,AI 通过当前任务上下文,能识别出我正在推进的任务是:
trellis-study-notes
它不只是知道名字,还会继续去读这个任务目录里的关键信息,比如:
task.jsonprd.md
而 prd.md 里已经写了这份笔记的目标、范围、阶段性结论和后续补写方向。
所以如果没有 Trellis,我每次都可能要重新解释这些事:
- 这份笔记到底是干什么的
- 现在写到第几章了
- 哪些章节已经成型
- 哪些章节还只是占位
- 当前这一轮到底准备补哪一章
但有了 Trellis,这些信息不再只靠聊天记录勉强维持,而是已经落在任务文件里了。
第四步:不是每次都从头解释,而是继续推进具体章节
在这次真实案例里,我和 AI 的协作不是“每次重新定义整份笔记”,而是:
进入上下文之后,继续推进当前具体章节。
比如这几轮里,我们做的就是:
- 把第 4 章“准备工作”从占位补成完整内容
- 把第 5 章“安装 Trellis”先对话澄清,再落成正文
- 现在继续进入第 6 章,用真实任务当案例
这正好说明了一件很关键的事:
Trellis 让任务的推进方式从“每次都像重新开题”变成了“我知道自己接下来在补哪一段”。
第五步:不同章节,可以用不同推进方式
这一点对我特别重要,因为它说明 Trellis 不是死板流水线。
在这份笔记任务里,不同章节其实用了不同的推进方式:
- 第 4 章更适合直接整理进文档,因为内容本身就是我已经实际做过的准备工作
- 第 5 章更适合先对话,因为它容易混淆“安装工具”“初始化项目”“开始会话”这几层
- 第 6 章又更适合把前面真实发生过的协作过程,反过来整理成案例
所以这章很值得记住的不是“标准流程长什么样”,而是:
在 Trellis 里,我可以带着任务上下文,决定这一步是先聊清楚,还是直接落文档。
这也是为什么我会越来越觉得,它不像一个死板命令系统,更像一个能跟着我节奏推进任务的工作框架。
第六步:任务的关键信息,不再只漂在聊天记录里
这是这一整章最想记住的地方之一。
在这次案例里,至少有三类重要产物已经落到了项目文件里:
- 任务本身,落在
.trellis/tasks/04-28-trellis-study-notes/ - 任务目标和边界,落在
prd.md - 实际整理出来的学习笔记,落在
trellis-study-notes.md
这意味着什么?
意味着这次实战真正重要的变化,不是“AI 临时回答得更聪明”,而是:
任务状态、需求边界、最终内容,都不只是漂在聊天记录里,而是落到了项目本身。
这一点对学习型任务尤其重要,因为这种任务最怕的就是:
- 这次聊清楚了
- 过几天又忘了
- 下一轮又得重新解释
而 Trellis 的价值,就是尽量把这些“聊清楚过的东西”转成可重新读取的项目状态。
第七步:这一类任务怎么收尾
这类文档型任务和纯代码任务的收尾方式也有一点不同。
这里最容易误会的一点是:
$brainstorm、$finish-work、$record-session、$update-spec 不是固定连招,而是分别对应不同阶段。
如果先按整条时序去记,会最清楚:
$start
先恢复当前项目和任务上下文$brainstorm
只在需求还不清楚时使用,用来先理清范围和边界- 做任务
写代码、写文档、补内容 $finish-work
在准备提交前做完工检查- 人工测试
自己再实际验证一遍这轮结果是不是对的 git commit
先把这一轮想保留的最新改动提交掉$record-session
再记录这次 session 做了什么$update-spec
只在这次工作沉淀出了可复用规矩时使用
所以对这类文档型任务来说,它更常经过的是:
- 改文档
- 视情况先用
$brainstorm把表达和边界聊清楚 - 检查内容
- 需要时用
$finish-work做提交前检查 - 自己再做一遍人工测试 / 手工确认
git commit$record-session
但我这次真实学到的一个点是:
如果上一次 commit 之后我又继续改了内容,那就要先把最新改动重新提交,再去做 $record-session。
不然记录下来的,就不是我真正想保存的最新状态。
所以对未来的我来说,这种持续整理型任务的收尾,可以先记成:
- 先确认文档已经补到这一轮想要的程度
- 如果这轮改动还没完全想清楚,就先继续对话,必要时用
$brainstorm - 准备提交前,先考虑要不要跑
$finish-work finish-work之后,自己再做一遍人工测试- 再确认最新改动已经提交
- 最后再考虑
$record-session
如果这一轮还额外总结出了“以后这个项目都适用的稳定做法”,再单独考虑$update-spec。
这一章最值得我记住的结论
这次实战真正让我感受到的,不是“AI 会帮我写文档”,而是:
Trellis 能帮我把一件会跨越很多轮对话的任务,稳定地继续推进下去。
对我来说,这比“瞬间生成一个待办 App”更有价值,因为它更贴近我之后长期真正会怎么用。
如果最后只记一句最短版,我会记成:
我不是每次都从头开始解释任务,而是在 Trellis 里持续接着做。
本章 3 句速记
- Trellis 不只适合代码开发,也适合像
trellis-study-notes这种会跨越多轮对话的整理型任务。 $start先恢复上下文,AI 再通过任务目录和prd.md继续推进当前章节,而不是每次重开题。- 真正有价值的是任务、边界和产物都落进了项目文件,而不是只漂在聊天记录里。
看懂工作流:AI 在背后做了什么
如果我要先给未来的自己一句最重要的话,我会先记成:
Trellis 的工作流不是某种神秘魔法,而是“把任务、规范、记录拆成几个阶段,再让 AI 先读文件、再做事”。
很多时候我会觉得它好像“自己就知道该干嘛了”,但如果把外壳拆开看,其实背后做的事情并没有那么玄。
它更像是在重复做这几件事:
- 先读当前项目状态
- 先找当前任务在哪
- 先看需求边界和项目规矩
- 再进入研究、实现、检查、记录这些阶段
所以这一章真正想讲清楚的,不是“AI 很厉害”,而是:
Trellis 到底靠哪些文件和状态,把一轮工作稳定地串起来。
先别把工作流想得太神秘
课件里会把它讲成一套看起来很完整的“AI 小团队”。这种讲法很好懂,但对我来说,更适合记成一个更落地的版本:
不是后台真的站着一排小人,而是 Trellis 把一轮工作拆成了几类职责。
最常见的几类职责可以先这样理解:
start:先恢复当前上下文brainstorm:需求不清时先收敛边界research:先看项目现状、现有模式和相关规范implement:真正改代码或改文档check:检查有没有漏项、有没有偏离规范record:把这次工作记录下来,方便下次接上
也就是说,Trellis 的核心不是“某个角色名称”,而是:
一轮任务不会直接从聊天跳到乱写,而是被拆成几个更稳的阶段。
在这个项目里,Trellis 实际会读什么
如果我以后又想问“它为什么知道我现在在做什么”,最应该先回头看这些文件和目录:
.trellis/workflow.md
这是整个项目的工作流说明.trellis/tasks/
这里放任务目录,每个任务都有自己的task.json和prd.md.trellis/.current-task
这里记录当前正在推进的是哪个任务.trellis/spec/
这里放项目规范和思考指南.trellis/workspace/
这里放 session 记录,也就是以后恢复上下文时会再次读回来的工作日志
所以 Trellis 真正的“记忆力”不是凭空长出来的,而是来自:
关键信息已经被提前拆开,放进了项目里的固定位置。
$start 之后,背后到底发生了什么
在我的实际使用里,最典型的入口就是:
$start
表面上看,只是我在对话里打了一句命令。背后更接近发生的是:
- 先读
.trellis/workflow.md - 再读当前 developer 身份和 git 状态
- 再看当前有没有活跃任务
- 如果有当前任务,再去读它的
task.json和prd.md - 再看有哪些 spec 索引和 guides 值得加载
所以 $start 真正的价值不是“开始工作”四个字,而是:
它会先把 AI 从普通聊天状态拉回当前项目状态。
这也是为什么我现在已经越来越不想每次都手动重复解释背景。
一个真实任务在背后会怎么走
如果拿这份 trellis-study-notes 来看,一轮真实工作背后更像是这样:
- 我说“继续第几章”
- AI 通过
$start或当前上下文,先确认现在正在推进的是trellis-study-notes - 它去读这个任务目录里的
prd.md - 它根据当前章节状态,判断这次是直接落文档,还是先短对话再落文档
- 写完之后,再根据情况进入检查、提交、记录这几个阶段
也就是说,真正让流程顺起来的不是“AI 突然变聪明”,而是:
任务目标、当前章节、前面已确认的边界,都已经先被项目状态固定住了。
任务为什么不是只靠聊天记住
我以前最容易忽略的一点是:
任务不是一句“帮我做 XXX”说完就结束了,它最好有自己单独的落点。
在 Trellis 里,这个落点就是任务目录。
比如这份笔记任务就落在:
.trellis/tasks/04-28-trellis-study-notes/
这里面至少会有两样很关键的东西:
task.json
记录任务身份、阶段、状态这些元信息prd.md
记录任务目标、范围、要求、边界和阶段性结论
所以以后我要记住:
任务目录很像一张长期存在的任务卡片,而不是一段会被聊天顶掉的临时消息。
prd.md 为什么这么重要
如果我只看表面,会觉得 prd.md 好像只是“多了一份文档”。
但它真正重要的地方在于:
它把原本只存在对话里的需求,压成了一个可以反复读取的结构化版本。
它会帮我固定住这些东西:
- 这次到底要做什么
- 哪些内容已经确认
- 哪些只是临时假设
- 哪些东西明确不做
- 现在最合理的推进方式是什么
所以后面我每次继续任务时,AI 不是在“猜我大概想干嘛”,而是在:
先读 prd.md,再在这个边界里继续干。
spec 为什么会影响 AI 的做法
除了任务本身,另一个会深刻影响 AI 行为的,就是:
.trellis/spec/
这里面放的不是任务内容,而是项目规矩。
最简单的区分方式是:
- 任务目录回答“这次要做什么”
- spec 回答“做的时候要遵守什么”
所以工作流里很关键的一步,不只是“找到任务”,还包括:
先看这次任务相关的规范和思考指南。
也正因为这样,Trellis 才不是单纯的任务管理器,它还是一个“把项目规矩喂给 AI”的系统。
工作流为什么会分成研究、实现、检查
如果没有 Trellis,最容易发生的就是:
- 需求刚说完
- AI 立刻就开始改
- 改完以后才发现理解偏了
- 或者风格不对
- 或者漏了上下文边界
Trellis 要解决的,就是把这种“直接冲”的路径拆开。
所以它会更强调这几个阶段:
- 先研究:看现有代码、现有模式、现有规范
- 再实现:按边界去写
- 再检查:看有没有偏掉、漏掉、冲突掉
如果我要用最白话的话记,可以记成:
先看清楚再动手,动完手再回头检查。
这就是为什么它的节奏通常会比普通聊天更稳。
workspace 和 record-session 在工作流里负责什么
还有一块特别容易被我低估的,就是:
.trellis/workspace/
这里放的是 session 记录,也就是一轮工作结束后留下来的“工作日志”。
这部分的价值不在于“写了一篇日记”,而在于:
下次继续工作时,AI 可以重新读回这次到底做了什么。
所以工作流真正闭环,不只是:
- 开始做
- 做完
而是:
- 开始前先恢复上下文
- 做的过程中有任务和规范约束
- 做完以后再把结果记回项目里
这样下一次才能真的接上。
任务状态切换,真正解决了什么问题
如果没有任务状态,很多事情都会变得模糊:
- 这次到底做到哪一步了
- 现在是在 brainstorm、implement 还是 check
- 这轮工作算没算完整
- 下次回来从哪里继续
而有了任务状态和当前任务指针以后,至少大方向不会漂得那么厉害。
所以 Trellis 在背后真正解决的,不只是“帮我写”,还有:
帮我把任务从“口头说过”变成“有状态、能恢复、能继续”。
如果只用一句话理解这一章
到这里我觉得最值得记住的,不是某个目录名,而是这句:
Trellis 的工作流,本质上就是“把任务、规范、记录都变成项目里能反复读取的状态”。
这样一来,AI 才不会每次都像第一次认识这个项目。
本章 3 句速记
- Trellis 背后的工作流没有那么玄,本质上就是先读项目状态,再按研究、实现、检查、记录几个阶段推进。
- 任务靠
.trellis/tasks/和prd.md固定边界,规范靠.trellis/spec/约束做法,session 靠.trellis/workspace/保留上下文。 - 它真正解决的不是“让 AI 更会说”,而是“让任务变成有状态、能恢复、能继续的项目过程”。
Spec 规范:教 AI “你家的规矩”
如果我要先给未来的自己一句最重要的话,我会先记成:
Spec 不是写给人看的漂亮文档,而是写给 AI 看的项目规矩。
这一章如果不先想清楚,后面很容易出现一种错觉:
- 我已经把需求说清楚了
- 为什么 AI 还是会写出我不喜欢的东西
原因通常不是 AI 完全没听,而是:
需求回答的是“这次要做什么”,Spec 回答的是“以后在这个项目里应该怎么做”。
这就是为什么 Trellis 里,任务和 Spec 是两套不同但互相配合的东西。
Spec 到底是什么
如果用最白话的话记,Spec 可以先理解成:
我写给 AI 的项目说明书。
它通常放在:
.trellis/spec/
下面。
它的作用不是描述“这一次任务的目标”,而是描述:
- 这个项目平时怎么写
- 哪些写法是推荐的
- 哪些写法是禁止的
- 哪些坑以后不要再踩
- 哪些边界在实现时必须先想到
所以以后我一定要把这两个问题分开:
- “这次要做什么”
看任务和prd.md - “做的时候该怎么做”
看.trellis/spec/
为什么光有任务还不够
这是我现在越来越能理解的一点。
任务可以把“目标”固定住,但它并不会自动告诉 AI:
- 组件文件该怎么命名
- 哪种写法在这个项目里算脏
- 错误处理该落在哪一层
- 哪些逻辑应该抽出去,哪些不该直接写死
也就是说,任务只解决“做什么”,但不完全解决“怎么做得像这个项目的人”。
而 Spec 的作用,就是把这部分补上。
所以 Trellis 真正强的地方不是只有任务系统,而是:
它会把任务边界和项目规矩一起喂给 AI。
初始化后为什么很多 Spec 还是空的
这一点很容易让人误会成“是不是没装好”。
其实不是。
初始化之后,.trellis/spec/ 里经常先只是一些模板或者空骨架,这很正常。因为 Trellis 不可能天然知道你的项目规矩到底是什么。
所以更准确的理解是:
Trellis 先把位置和结构搭好,真正的项目规矩要靠你后面逐步补进去。
这也是为什么课件里会强调:
不用一口气写完,项目做到哪,规范补到哪。
这句我觉得非常重要,因为它能防止我一开始就陷入“我要先写完整套规范才能开始做事”的拖延里。
一个好的 Spec 大概长什么样
如果我以后再问“那规范到底该怎么写”,最简单的答案不是理论,而是结构。
一个比较像样的 Spec,通常会包含这些内容:
- 必须遵守的规则
- 推荐写法 / 好的例子
- 不要这么写 / 坏的例子
- 常见错误或容易踩的坑
也就是说,它不是只写一句空话,比如:
- 要保持代码整洁
- 注意类型安全
- 提高可维护性
这种话太虚了,AI 看了也很难真正执行。
更有用的规范,应该更像:
- 组件文件名用什么格式
- 哪种请求逻辑不能直接写在组件里
- API 的日期字段用哪种格式
- 出错时应该在哪一层处理
- 哪类写法在这个项目里算禁用
所以以后我要记住:
好的 Spec 不是漂亮口号,而是能直接指导实现的具体规则。
在这个项目里,Spec 不只是一层
这是我前面已经逐渐想清楚的一个边界。
.trellis/spec/ 下面通常不只是一堆平铺的文件,而是会分层:
.trellis/spec/backend/
放后端怎么实现的规则.trellis/spec/frontend/
放前端怎么实现的规则.trellis/spec/guides/
放做之前要想到什么的思考指南
这三层不能混着理解,而且最好直接记住它们各自回答的问题:
backend/回答:后端代码以后该怎么写frontend/回答:前端代码以后该怎么写guides/回答:开始做之前,我应该先想到什么
如果我要把使用场景说得再直白一点,可以这样分:
什么时候看 backend/
当任务主要在这些地方时,更应该优先看 backend/:
- API
- 数据库
- 服务层
- 错误处理
- 日志
- 命令脚本
- 后端目录结构和实现约定
也就是说,只要我更关心的是:
后端这段代码应该怎么写、怎么组织、怎么处理边界。
那就更该去看 backend/。
什么时候看 frontend/
当任务主要在这些地方时,更应该优先看 frontend/:
- 组件
- hooks / composables
- 页面结构
- 状态管理
- 类型约束
- 前端目录结构和实现约定
也就是说,只要我更关心的是:
前端这段代码应该怎么写、怎么拆、怎么保持风格一致。
那就更该去看 frontend/。
什么时候看 guides/
当我还没开始写,或者我最怕的是“有些事根本没想到”,这时更该先看 guides/。
它更适合这种情况:
- 这次是不是跨层改动
- 这次是不是要先想复用
- 这次是不是改了常量、配置或共享逻辑
- 这次是不是在继续一个长任务,不确定该直接写还是先 brainstorm
- 这次是不是快要
$record-session了,但我还没确认 commit 状态
也就是说,guides/ 不是告诉我最终代码长什么样,而是提醒我:
开始做之前,有哪些方向我最好先过一遍脑子。
所以最简单的区分方式就是:
- “这是以后代码该怎么写”
放backend/或frontend/ - “这是以后做事前该先想到什么”
放guides/
比如:
- “日期字段统一用 ISO 8601 字符串”
这更像实现规范,应该偏backend/或跨层相关规范 - “改常量前先全局搜索一遍”
这更像思考提醒,应该偏guides/ - “组件文件名统一用大驼峰”
这更像前端实现规范,应该偏frontend/ - “先判断需求清不清楚,再决定要不要 brainstorm”
这更像工作流提醒,应该偏guides/
如果最后只记一句最短版,我会记成:
backend / frontend 管‘怎么写’,guides 管‘先想到什么’。
guides 和真正的 Spec 有什么区别
这点如果不提前讲清楚,后面很容易什么都往一个地方塞。
我现在最适合给未来自己的理解是:
Spec 更像“怎么写”,Guide 更像“先想到什么”。
Guide 不应该把所有实现细节再重复一遍,它更像一个提醒清单。
比如:
- 这次是不是跨层改动
- 这次是不是改了常量或配置
- 这次是不是应该先想复用
- 这次是不是有边界条件没想到
所以以后如果我发现自己在写“提醒自己别漏掉什么”,那通常更像在写 guides/。如果我在写“以后代码就按这个规则实现”,那通常更像在写真正的 Spec。
什么时候应该补 Spec
这个问题其实比“Spec 是什么”还重要。
因为大多数时候,不是我完全不知道 Spec 有用,而是我不知道:
到底什么时候值得补,什么时候只是普通任务记录。
一个比较稳的判断方式是看这次学到的东西有没有“复用价值”。
更适合补 Spec 的情况通常是:
- 我发现了一个以后会反复遇到的模式
- 我踩到了一个以后很容易再踩的坑
- 我明确了一个设计决定,以后不想每次重新争论
- 我修掉了一个跨层问题,顺手总结出了更稳定的规则
- 我发现某个顺序必须先做 X 再做 Y
不太适合补 Spec 的情况通常是:
- 只是这次任务里的临时表述
- 只对当前这一章文字组织有效
- 还没有稳定到能叫“项目规矩”
所以一句话记忆:
不是每次做完任务都要补 Spec,而是当我学到的东西已经值得变成“以后都适用的规则”时,再补。
$update-spec 在这里扮演什么角色
到了这里,前面第 9 章里讲过的 $update-spec 就能和这一章接上了。
$update-spec 不是普通日志命令,它更像是在问:
这次任务里,有没有什么经验值得升格成项目规矩?
如果答案是有,那它就会帮我把这些东西往 .trellis/spec/ 里落。
也就是说:
$record-session解决的是“这次做了什么”$update-spec解决的是“以后都该怎么做”
这两个不是一回事。
对这份学习笔记任务来说,哪些东西该不该进 Spec
这个边界对我现在特别重要。
因为我现在很多思考都发生在整理这份笔记的过程中,但不是每个思考都该直接进项目 Spec。
比如下面这类内容,更适合继续留在笔记里:
- 第 5 章我想先偏小白安装版,还是偏实战理解版
- 这一段我想用类比讲,还是直接讲
- 这章语气是不是更像写给未来的自己
这些更像当前文档策略,不一定是项目级规矩。
但下面这类东西,就更有可能值得进 Spec 或 guides:
- 文档型任务什么时候更适合先对话再落文档
record-session之前必须先确保最新改动已经提交- 需求不清时先用
$brainstorm,不要直接冲进实现 - 某种跨层错误以后该怎么固定防住
所以以后我得学会分辨:
这次只是我自己的理解过程,还是已经长成了“以后这个项目都适用的规则”。
Spec 和代码之间到底是什么关系
这一章如果只停在“Spec 很重要”,其实还不够。
我现在更想记住的是:
Spec 和代码不是两份互不相干的东西,而是“规矩”和“执行结果”的关系。
更理想的状态应该是:
- 我先做任务
- 在实现或复盘中发现稳定模式
- 再把这个模式补进 Spec
- 下一次 AI 做类似任务时,先读到这个规则
- 于是后面的代码更容易一开始就走对
这也是为什么 Spec 会形成一种飞轮:
- 踩坑
- 总结
- 写进 Spec
- 以后自动避坑
所以项目做得越久,Spec 越清楚,AI 也就越像真的“懂这个项目”。
如果我不知道该怎么写 Spec,怎么办
这一点课件里说得很实用,我也想直接记下来:
不知道怎么写时,不要卡住,可以先让 AI 根据现有代码起草。
比如可以让 AI 去看当前项目已有代码和已有模式,再帮我起一版:
- frontend 规范草稿
- backend 规范草稿
- 某个具体主题的规范草稿
然后我再去删、改、补。
所以起步时最现实的做法不是“凭空写一整套完美规范”,而是:
先让它根据现状起草,再逐步改成真正像我项目的规则。
如果只用一句话理解这一章
到这里我觉得这一章最值得记住的是:
Spec 的作用,是把“这个项目以后该怎么做”提前写下来,让 AI 每次干活前先读规矩。
任务让 AI 知道“做什么”,Spec 让 AI 知道“怎么做得像这个项目的人”。
本章 3 句速记
- Spec 是写给 AI 看的项目规矩,不是写给人看的漂亮口号。
- 任务回答“这次要做什么”,Spec 回答“以后在这个项目里应该怎么做”。
- 不是每次做完任务都要补 Spec,而是当经验已经值得变成项目级规则时,再用
$update-spec落进.trellis/spec/。